The Survival of the Fittists
By Howard Wainer
Understanding the role of replication in research is crucial for the interpretation of scientific advances
Understanding the role of replication in research is crucial for the interpretation of scientific advances

DOI: 10.1511/2012.98.358
The concept of replicability in scientific research was laid out by Francis Bacon in the early 17th century, and it remains the principal epistemological tenet of modern science. Replicability begins with the idea that science is not private; researchers who make claims must allow others to test those claims. Over time, the scientific community has recognized that, because initial investigations are almost always done on a small scale, they exhibit the variability inherent in small studies. Inevitably, as a consequence, some results will be reported that are epiphenomenal—false positives, for example. When novel findings appear in the scientific literature, other investigators rush to replicate. If attempts to reproduce them don’t pan out, the initial results are brushed aside as the statistical anomalies they were, and science moves on.
Scientific tradition sets an initial acceptance criterion for much research that tolerates a fair number of false positives (typically 1 out of 20). There are two reasons for this initial leniency: First, it is not practical to do preliminary research on any topic on a large enough scale to diminish the likelihood of statistical artifacts to truly tiny levels. And second, it is more difficult to rediscover a true result that was previously dismissed because it failed to reach some stringent level of acceptability than it is to reject a false positive after subsequent work fails to replicate it. This approach has meant that the scientific literature is littered with an embarrassing number of remarkable results that were later shown to be anomalous.
A wonderful example of this effect originated in the 1930s at Duke University. J. B. Rhine, a botanist turned parapsychologist, designed studies that he hoped would discover people with extrasensory perception (ESP). He thought he had found one in Adam Linzmayer, an economics undergraduate at Duke. In spring 1931, as a volunteer in one of Rhine’s experiments, Linzmayer performed far better than chance suggested he should. In subsequent experiments his performance retreated back to chance. Rather than dismiss the initial finding, Rhine concluded that Linzmayer’s “extra sensory perception has gone through a marked decline.” But Rhine kept searching for people with ESP talent until he encountered another experimental subject, Hubert Pearce, who had a remarkable run of successes before he too suffered the loss of his psychic gift. This spotty record did not deter the energetic Rhine. The University of Chicago researcher Harold Gulliksen wrote a scathing review of Rhine’s 1934 opus Extra-Sensory Perception, suggesting that although the statistical methods Rhine used were seriously flawed, he would not discuss them for fear that he would distract attention from the monumental errors in Rhine’s experimental design. (For example, if you looked carefully at the cards he used to test subjects, you could see an outline of their patterns from the reverse side. Such flaws are often overlooked by scientists inexperienced in magic. Stanford statistician and magician Persi Diaconis spent a fair amount of time debunking claims of ESP made by Uri Geller and others. Diaconis proposed that he was uniquely qualified for such a task; magicians couldn’t do it because they didn’t understand experimental design, and psychologists couldn’t do it because they didn’t know magic. His claim has subsequently been borne out by evidence.)

Photo courtesy of Duke University Archives.
Rhine’s reaction to and interpretation of normal stochastic variation provides an object lesson in how humans, even scientists, allow what they want to be true to overwhelm objective good sense. Nobel Prize Laureate Daniel Kahneman spends the 500 pages of his recent book, Thinking, Fast and Slow, laying out how and why humans behave this way. It is left to scientists to remember this tendency as we do our work.
Alas, the shrinking size of scientific results is not a phenomenon confined to scientific exotica like ESP. It manifests itself everywhere and often leads the general public to wonder how much of the scientific literature can be believed. In 2005 John Ioannidis, a prominent epidemiologist, published a paper provocatively titled “Why Most Published Research Findings Are False.” Ioannidis provides a thoughtful explanation of why research results are often not as dramatic as they were first thought to be. He then elaborates the characteristics of studies that control the extent to which their results shrink upon replication.
None of Ioannidis’ explanations came as a surprise to those familiar with statistics, which is, after all, the science of uncertainty. Larger studies with bigger sample sizes have more stable results; studies in which there are great financial consequences may more often yield biases; when study designs are flexible, results vary more. The publication policies of scientific journals can also be a prominent source of bias.
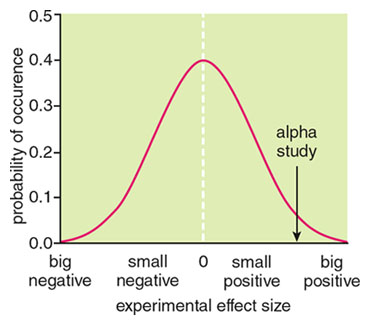
Let me illustrate with a hypothetical example. Assume that we are doing a trial for some sort of medical treatment. Furthermore, suppose that although the treatment has no effect (perhaps it is the medical equivalent of an ESP study) it seems on its face to be a really good idea. To make this more concrete, imagine that modern scientific methods were available and trusted in the 19th century, and someone decided to use them to test the efficacy of using leeches to draw blood (which was once believed to balance the bodily humors and thence cure fevers). If a single study was done, the odds are it would find no effect. If, over a long period of time, many such studies were done, we might find that most would find no effect, a fair number would show a small negative effect and an equal number a small positive effect—all quite by chance. But chance being what it is, if enough studies were done, a few would show a substantial positive effect—and be balanced by a similar number that showed a complementary negative effect (see the figure below).
Of course, if we were privy to such a big-picture summary, we could see immediately that the treatment has no efficacy and is merely showing random variation. But such a comprehensive view has not been possible in the past (although there is currently a push to build a database that would produce such plots for all treatments being studied—the Cochrane Collaboration). Instead what happens is that researchers who do a study and find no significant effect cannot publish it; editors want to save the scarce room in their journals for research that finds something. Thus studies with null, or small, estimates of treatment effects are either thrown away or placed in a metaphorical file drawer.
But if someone gets lucky and does a study whose results, quite by chance, fall further out in the tail of the normal curve, they let out a whoop of success, write it up and get it published in some A-list journal—perhaps the Journal of the American Medical Association , perhaps the New England Journal of Medicine. We’ll call this the alpha study. A publication in such a prestigious journal garners an increase in the visibility of both the research and the researcher—a win-win.
The attention generated by such a publication naturally leads to attempts to replicate; sometimes these replication studies turn out to have been done before the alpha study, lending support to the hypothesis that the alpha study might be anomalous. Typically these studies do not show an effect as large as that seen in the alpha study. Moreover, the replication studies are not published in the A-list journals, for they are not pathbreaking. They appear in more minor outlets—if they are accepted for publication at all.
So a pattern emerges. A startling and wonderful result appears in the most prestigious of journals, and news of the finding is trumpeted in the media. Subsequently, independent studies also appear, but few are seen by a significant number of readers, and fewer still are picked up by the media to diminish the impression of a breakthrough generated by the alpha study. Sometimes, though, news of diminished efficacy percolates out to the field and perhaps even the public at large. Then we start to worry, “Does any treatment really work?”
One version of this effect, delineated in a 1995 paper by Geneviève Grégoire and her colleagues at the Hôtel-Dieu de Montréal in Quebec, has come to be called the Tower of Babel bias. The authors considered meta-analyses published in eight English-language medical journals over a period of two years. The advantage of a meta-analysis is that it combines the findings of many other studies in an effort to establish a more rigorous conclusion based on the totality of what has been done. More than just a research review, it allows each study to be weighted proportional to its validity. Grégoire and her colleagues found that a majority of the analyses excluded some studies based on language of publication, and that the analyses’ results might have been altered had they included studies published in languages other than English. More generally, it is almost a truism by now that studies whose results either do not achieve statistical significance or show only a small effect are published in local journals or not at all. Thus international estimates of treatment effects tend to have a positive bias.
The stage is now set for us to shift our gaze to research done in the East. Chinese medical research, for example, is almost invisible to Western scientists, but the reverse is not true: Chinese researchers seem well aware of major findings in the West, although they are probably less familiar with the more minor publications. Keeping in mind the phenomenon of shrinking effect sizes, if we looked carefully at the findings of Chinese medical researchers as they strive to replicate Western medical findings, we would expect to find the same shrinkage as is the rule in the West. Is this what happens?
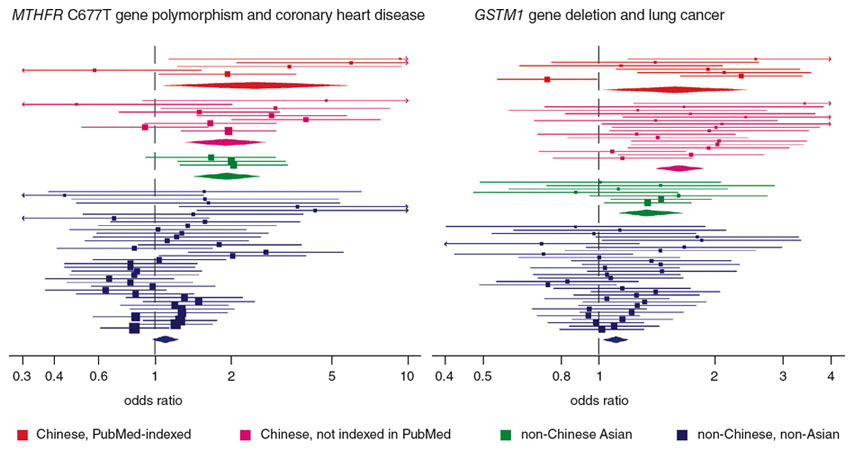
Figure adapted from Pan, Z., et al. 2010. PLoS Medicine 7:e334.
Zhenglun Pan, of Shandong Provincial Hospital in Shandong, China, and a team of international scholars did a large meta-analysis of dozens of studies done in China that were meant to be replications of earlier studies. They then redid the same meta-analysis with studies from other Asian (but non-Chinese) researchers, as well as non-Asian, non-Chinese researchers. The studies they considered, in the field of genetic epidemiology, seemed to find effect sizes at or surpassing those found in the alpha study. The authors call this a “reverse Tower of Babel” bias. Although the bias was greatest in Chinese studies, it was also found, to a lesser extent, in non-Chinese Asian research. Replication studies on the same subject by non-Chinese, non-Asian researchers found the smallest effect sizes of all. (Summaries of two of the meta-analyses by Pan and colleagues are shown on the facing page.) Several speculative reasons for this effect come to mind—perhaps it is a matter of cultural norms; perhaps there is an interaction between treatment and ethnicity. Thus far we must await further research to determine its sources.
Science is designed to be self-correcting. Attempts to replicate provide evidence of when it has gone astray. Or at least that’s the theory. The real world, filled with fallible people and institutions, practically guarantees that the path toward progress meanders, sometimes massively. But this is not all bad. As physicist David Deutsch has emphasized, the evolution of a scientific idea is different than the Darwinian evolution of an organism in at least two important ways. First, ideas evolve in ways that are directed by the intelligence of the investigators. In contrast, biological evolution has no goal other than maximizing the likelihood that a particular mixture of genes will spread. Second, if a particular phenotype emerges that cannot survive, it becomes an evolutionary dead end, but an idea that is a failure can still have parts that can be retrieved and used subsequently.
The story told here provides some compelling examples, if any were needed, that the road to improvement is fraught with potholes of misinformation and twists of political intrigue. But as long as we maintain a healthy skepticism and remain free to publicly question the status quo, we will continue to advance—at least for those disciplines for which the direction of an advance is known. In a 1966 American Scientist article, Princeton University psychologist Julian Jaynes offered an evocative metaphor to delineate what he saw as the differences between psychology and physics. I would apply Jaynes’s words more broadly to the differences between the hard sciences and the humanities—and, to some extent, the social sciences:
Physics is like climbing a mountain: roped together by a common asceticism of mathematical method, the upward direction, through blizzard, mist, or searing sun, is always certain, though the paths are not. . . . The disorder is on the ledges, never in the direction. . . .
[Psychology] is less like a mountain than a huge entangled forest in full shining summer, so easy to walk through on certain levels, that anyone can and everyone does. The student’s problem is a frantic one: he must shift for himself. It is directions he is looking for, not height. . . . Multitudes cross each other’s paths in opposite directions with generous confidence and happy chaos. The bright past and the dark present ring with diverging cries and discrepant echoes of “here is the way!” from one vale to another.

The pitons and cleats so critical for ascending a mountain, Jaynes continues, are replaced with blinders and earplugs as people wander the forest. This passage may help explain why the scientific method, so powerful in the hard sciences, fails when applied to subjects in which there is no broad consensus of what constitutes an advance.
In the world we inhabit, the rules of science interact with the foibles of scientists. What we see should not be taken at face value—even “objective science.” Every scientific study carries along with its results some sense of its own credibility. Studies with larger sample sizes are more credible than those that are smaller, ceteris paribus. If those doing the study have a great deal riding on the result, credibility suffers. We must always be vigilant. But the current, flawed system, in which independent studies are used to test results obtained by someone else, is the best available. As flaws are detected, we can institute reforms. Such reforms should always move in the direction of greater openness and greater accessibility to the raw data from which the conclusions are drawn.
The success of the scientific method relies on the continued existence and prosperity of researchers who relentlessly fit experimental data to theory. The validity of science depends on the survival of the fittists.
I am thankful to David Donoho who, over dinner one evening, told me about the results of a meta-analysis of Chinese medical research, thus instigating the writing of this essay.
Click "American Scientist" to access home page
American Scientist Comments and Discussion
To discuss our articles or comment on them, please share them and tag American Scientist on social media platforms. Here are links to our profiles on Twitter, Facebook, and LinkedIn.
If we re-share your post, we will moderate comments/discussion following our comments policy.