How Many Ways Can You Spell V1@gra?
By Brian Hayes
Spam mutates, and the Internet community mounts an immune response
Spam mutates, and the Internet community mounts an immune response

DOI: 10.1511/2007.66.298
What's most remarkable about the question posed in my title is that I probably don't need to explain it. If you have checked your e-mail anytime in the past few years, you know all about "V.i.a.g.r.a" and "V!A6RA" and "\/lagra," not to mention "C1aL|$" and "Rrol,x Rep,ica" and—let's not be bashful about this—"pen1s en1argement." As spam has been proliferating in everyone's inbox, it has also been mutating madly, presumably in an effort to evade the filters that most of us now have in place.
I wrote a column on spam four years ago, when the plague was still in its early stages. I reported then, in breathless amazement, that I was getting as many as 300 spams a month! Now, if the tally ever dropped that low, I would worry that something had gone wrong with my Internet connection. Spam has become one of modern life's little assaults on our patience and dignity, like traffic jams and cell-phone ringtones and getting wanded at the airport. We all hope it will just go away, but in the meantime we learn to live with it. One way of coping is to set your emotions aside and look upon the irritant as an object of dispassionate study.
At the deepest level, spam is a social and economic phenomenon rather than a technological one. The senders and the intended recipients are people, not computers. Nevertheless, there's the potential for some interesting computation in the making of the stuff, and even moreso in the defenses that help keep it in check. Cre@tive spe11ing is part of this story, and so is the automated production of meaningless drivel. On the defensive side, tools from statistics, pattern analysis and machine intelligence have been brought to bear. Twenty years ago, who could have guessed that the most widely deployed application of computational linguistics and computational learning theory would be fending off nuisance e-mail?
The spam we see today is shaped in many ways by our own efforts to combat it. The process is often likened to an arms race, with threats met by countermeasures, which then bring countercountermeasures, and so on. I prefer an immunological metaphor, where the contest is between a host organism and pathogens or parasites, and where both sides have to adapt and evolve in order to survive. In the case of bacteria and viruses, the vast majority never make it, but nature is profligate and can afford such high attrition; likewise spammers find it worth their while to send a million e-mails for a handful of responses.
Some organisms have "hard-wired" resistance to infection; they produce molecules—natural antibiotics—that inhibit the growth of certain bacteria. The mammalian immune system works differently; we are not born with specific defenses against Salmonella or measles. Instead, a random shuffling mechanism generates a vast array of defensive molecules, which have the potential to attack virtually anything they might encounter in the environment. Before going into action, however, the system must learn to distinguish friend from foe. This strategy has a cost: Because learning is a slow process, you may well get sick the first time you are exposed to an infectious agent. But the alternative of relying on a predetermined list of potential threats would be even more perilous, since any novel pathogen would meet no resistance at all.
The option of exploiting random variation is also available to the opposition. Indeed, the pathogens that pose the greatest danger of epidemic outbreaks are those that mutate rapidly and randomly, changing their outward appearance to evade immune-system surveillance.
It's easy to draw parallels between these biological concepts and the co-evolution of spam and antispam technologies. When the first unwanted bulk e-mails appeared, the recipients deleted them manually. As the volume increased (and along with it the level of irritation), savvy network users wrote simple programs to automate the deletion process. These early filtering programs, many of which were created with the Unix tool procmail, relied on static, hand-crafted rules to recognize spam. For example, a message might be rejected if the phrase "Free softwares!!" appeared in the subject line. The weakness of this system is that new rules are needed when the next spam advertises "Cheap softwares!!"
The procmail approach to spam filtering corresponds to the biological strategy of synthesizing a separate antibiotic for each type of bacterial infection. A more versatile filter, analogous to the mammalian immune system, can learn to recognize virtually any category of message, based on whatever characteristics of the text happen to be most salient. These distinctive markers are the counterparts of antigenic sites, or epitopes, on the protein molecules that label a virus or bacterium as foreign. The adaptive spam filter doesn't work from a predefined list of suspect phrases but rather discovers the most telling signs by exposure to spam and legitimate e-mail.
Whatever the mechanism of the filter, the spam writer can respond by varying the message. If e-mail containing the word "Viagra" is blocked, there are other ways of getting the idea across, including synonyms and circumlocutions ("sildenafil citrate," "impotence meds," "the little blue pill"). An adaptive filter will soon flag these terms as well, but by then the spammer can move on to other options. For some kinds of variation—such as obfuscatory misspelling along the lines of "V1@gra"—computational methods could automate the generation of random variants.
So how many ways can you spell Viagra? The question is addressed directly by an amusing Web page, created by Rob Cockerham of Sacramento, whose title announces: "There are 600,426,974,379,824,381,952 ways to spell Viagra." (The page pokes fun at Viagra spam, but it carries advertisements from NetDr.com, selling you-know-what.)
Cockerham gets his number from a combinatorial analysis. He starts by tabulating the various possible substitutions for each of the five letters V, I, A, G and R. For example, any the 12 characters I, i, 1, l, |, ï, ì, :, Ì, Î, Í or Ï might serve for an I. Considering just such one-for-one substitutions, Cockerham comes up with 3×12×17×2×3×17 variations, for a total of 62,424 spellings.

Brian Hayes
Where do the rest of the 6×1020 possibilities come from? Cockerham observes that the spelling can also be altered by inserting extraneous characters into the word, as in V_i_a_g_r_a. Taking the basic pattern to be *V*I*A*G*R*A*, where each asterisk could be replaced by any of 192 printable characters, he multiplies 1927 by 62,424 to get the total cited above. (An addendum mentions a few more substitution possibilities, bringing the total to 1,300,925,111,156,286,160,896.)
It's always a treat to see combinatorial methods hard at work in everyday life, but I'm afraid I don't find this result quite credible. If the aim is to fool computers while producing something still recognizable by the human reader, then the pure substitutions work reasonably well. Even something as weird as V|@6®A can probably be understood if the context offers enough clues. On the other hand, applying the unconstrained insertion algorithm produces strings of characters so obscure that neither man nor machine could readily parse them. And combining substitutions with random insertions leads to nothing but cartoon cursing: g\/Sl*aT9©rÜ@´.
Ascending to a still loftier plane of absurdity, we could allow any number of insertions at any point within the word. Then Viagra would be everywhere. (In a dictionary search the shortest example I found was "vicar general.")
If we want to count only those spelling variants that are readable without cryptographic aids, we should probably limit the insertable characters to punctuation marks and spaces. At the same time, however, other techniques that Cockerham did not consider, such as doubled letters (Viiaggra), could be included. The result of this calculation would be a number much smaller than 1020, and yet even by a conservative measure it seems safe to say there are at least a million ways to spell Viagra.
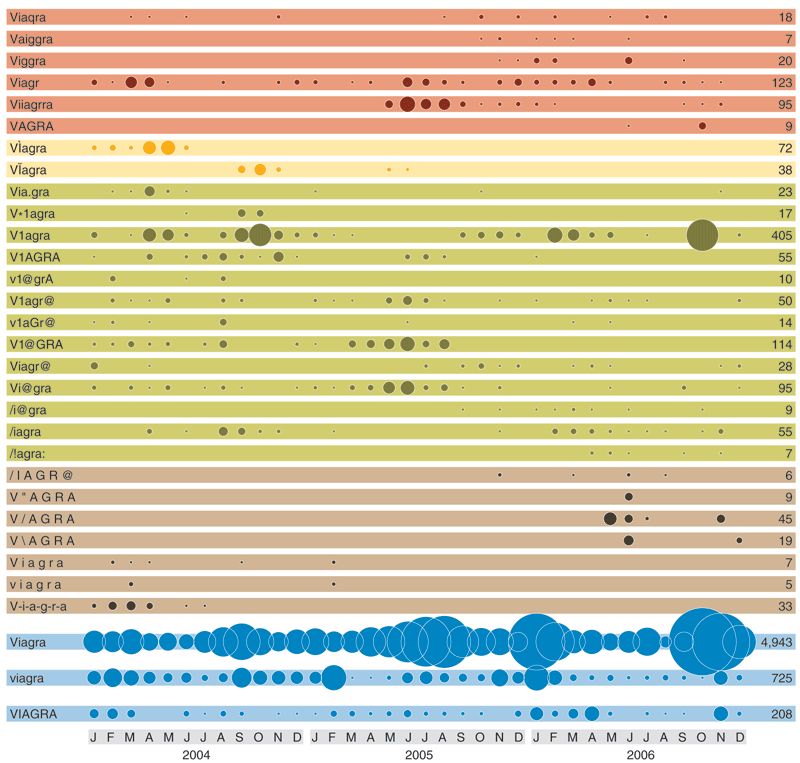
When I first noticed spam with aberrant spellings, I assumed that someone out there in the murky world of spam service providers had written a program to generate random variants. It's not hard to do so. At the core of the program is a grammar that defines all possible ways of forming an acceptable spelling. The illustration on this page gives an example of such a grammar, one that allows substitutions and a limited form of insertions. The grammar could be improved with a few context-sensitive rules; for example, the numeral "6" might be chosen as a substitute for "G" only when it is surrounded by upper-case characters; in a lower-case context, "9" would be a better choice.
With a program generating random variants and inserting them into the text of a message, every recipient of a mailing could get a customized version. (What a thrill: your very own personalized spam!) Even if many mailings used the same algorithm, so that not all the spellings were unique, it's unlikely that any one recipient (or, more to the point, any one spam filter) would see the same spelling twice.
Brian Hayes
I still suspect that such random-spelling generators exist in the spam world, but the evidence of my own inbox suggests they are not widely used. The telltale mark of their use would be a peculiar abundance of hapax legomena—the lit-crit term for words that appear only once in a corpus. As a first step in looking for such throwaway spellings, I read through a sample of about 10,000 spam messages, extracting every variant of "Viagra" I could find. (I excluded cases where the term was obfuscated not by misspelling but by other techniques, such as embedding HTML tags between the letters.) At the end of this bleary-eyed task I had 113 spellings. I then ran a search program over all the spam I had received in the course of three years, counting the number of occurrences of each of the spellings.
There were indeed a few hapax legomena, and some of them exhibited a family resemblance, suggesting that they might all be output of the same algorithm. For example, VtAGGReA, VttAGGRA and VtAGGjRA each appeared exactly once in the corpus of 88,324 messages, all within a period of a few days in June 2006. Perhaps these strangely malformed words are the product of a Perl script running on some spammer's clandestine mail server. Or maybe they're just someone strumming on the keyboard. In either case, it appears the experiment was not a great success. Nothing similar has turned up since.
Certain other spellings also seem to come in families, such as VÌagra, VÏagra, V1agra and V1AGRA, but these examples are definitely not dynamically generated variants that are meant to be unique to each message. They arrived in my mailbox in big bunches, often several copies a day. The V1agra spelling appears more than 400 times in my three-year collection.
The spelling variations (as shown in the illustration ["Spelling 'Viagra'"]) might be likened to the spectrum of genetic mutations in a population of bacteria. The Viagra variants offer some tentative hints about the working habits of spammers. Often, once a spelling has been incorporated into a message, it is mailed out repeatedly over a period of a few months, then given a rest. The conspicuous vertical correlations within the diagram suggest that mailings with the various spellings are not independent. A plausible inference is that most of the pill-pushing spam comes from a few individuals.
Among all the spellings, the most popular by far were the plain, unadorned ones: Viagra, viagra and VIAGRA. There's a bit of a conundrum here. If mangled spellings are necessary to get a message through the spam filters, then what's the point of sending thousands of undisguised ones? And if the mangling isn't really needed, then why go to the bother of producing all those variants? For what it's worth, the spam filter running on my computer seems quite indifferent to all these shenanigans: With very few exceptions, all of the Viagra messages, no matter how they spell it, go directly to the junk folder.
The techniques used to combat spam are much better known than the methods of spam senders, for the simple reason that authors of spam-fighting tools publish in the open literature. The antispam measures are quite diverse (which is surely a virtue). There are blacklists and whitelists and even graylists, and various schemes to authenticate senders. There have also been many proposals for legal or economic remedies, or changes to network protocols. But the most widespread tactic for thwarting spam is filtering—analyzing the content of individual messages in an effort to distinguish unwanted from wanted messages. Insiders call them spams and hams.
When procmail rule sets became too unwieldy, attention turned to filters based on ideas from computational learning theory. Underlying this approach is the insight that people can tell at a glance whether a message is spam or ham, but they cannot always articulate the reasons behind their judgment or give clear criteria that can be applied to future messages. Thus an efficient division of labor is to let the human reader serve as final arbiter of what is spam and what is ham, while letting the program discern which features of messages are most useful in defining the two categories. Interestingly, the features identified by the software are often ones that human readers don't notice at all.
Initially, a filter program can be trained on a corpus of pre-classified messages. Thereafter, training continues as the human user corrects any errors of classification.
The first experiments with trainable spam filters were reported in the late 1990s. Patrick Pantel and Dekang Lin of the University of Manitoba built a program called SpamCop, and another project based on similar principles was undertaken by Mehran Sahami of Stanford University and Susan Dumais, David Heckerman and Eric Horvitz of Microsoft Research. The idea attracted a lot more attention four years later when it was rediscovered by Paul Graham, an independent writer and programmer, who issued a manifesto titled "A Plan for Spam." Since then, dozens of commercial products and open-source programs have come into use.
The buzzword associated with these projects is Bayesian, after the 18th-century cleric and mathematician Thomas Bayes; in some cases it is further qualified as naive Bayesian. The nature of the e-mail is inferred from a statistical weighing of various features. In this context a feature might be anything from the presence of the word "Viagra" to the number of exclamation points in a message. Given a set of preclassified messages, it is straightforward to tabulate the frequency of each such feature in each class and thus to calculate the probability that a feature will appear in a spam or ham message. Bayes's theorem offers a mathematical armature for making the inverse calculation: Given the presence or absence of certain features in a message, determine the probability that the message is either spam or ham. The naive variant makes the simplifying assumption that all the features are independent.
A filtering program starts by breaking a message down into a sequence of tokens, which could be words or numbers or perhaps special entities such as components of e-mail addresses. During the training phase, each token is entered into a database and assigned a "spamminess" score. In the simplest case the spamminess could just be the token's frequency in spam messages divided by its frequency in all messages, but in practice various minor adjustments are made.
When the filter is applied to a newly arrived e-mail, each token from the message is looked up in the database. The spamminess scores of these tokens make a prediction about the status of the new message. But the predictions may be contradictory. How do you choose which ones to believe, and how do you combine them to reach a decision? Some of the early filtering programs included information from all the tokens, but later authors found that accuracy improved when the program considered only those tokens with the most extreme spamminess scores (close to 0 or close to 1). As for how to combine the values, Graham adopted the formula
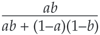
where a and b are the spamminess predictions of two tokens. (The formula can readily be extended to an arbitrary number of tokens.) This is not quite the formula suggested by the Reverend Bayes; Graham neglects to adjust for differences in the overall probability of spam and ham. Nevertheless, the filter performs remarkably well.
In a way, what's most impressive about this technique is how crude and superficial is it—and yet it works. There is no attempt to divine the meaning of the message. The filter's judgment is based on weighing a multitude of tiny features, like the minutiae of fingerprints. The basic technology of Bayesian text classification was first developed for more general tasks, such as the automated filing, sorting and indexing of documents. Spam filtering is just a special case of this method, but an unusually difficult one, if only because it's an adversarial process: There's someone out there trying to fool the filter.
All the zany spellings discussed earlier are presumably part of the adversary's strategy for slipping through the anti-spam net. When a message arrives trying to sell you "VtAGGjRA," your spam filter probably doesn't have a score for that token. Some of the obfuscation techniques are even more insidious, in that they disrupt the low-level process of forming tokens. The spelling "V i a g r a" might well be taken as six separate tokens.
Some of the wiles of spammers may be intended not just to evade detection but also to sabotage the filter. The idea is called Bayesian poison. Many spams include a long addendum of random words or irrelevant text, such as paragraphs lifted from Dickens or Defoe, or recent news items. One aim of this practice is to dilute the spamminess of the message, so that the overall score might fall below the rejection threshold. But there could be a more nefarious effect as well. If the message does wind up in the spam bin, then all its "innocent" words will have their spam scores increased slightly. Eventually, legitimate messages that happen to mention those words may be falsely condemned as spam. Returning to the immunological metaphor, Bayesian poison induces something like an allergy or an autoimmune disease.
Opinions differ on whether Bayesian poisoning is a threat we need to worry about. An article by John Graham-Cumming, which reviews experiments by several groups, concludes that the attack is likely to succeed only if the spammer can get feedback on which messages succeed in fooling the filter. And frequent retraining of the filter is an effective defense.
Paul Graham argues that many attempts to disguise spam actually make it stand out more prominently. After all, few legitimate correspondents spell words with 1's and @'s in the middle, or quote long passages from Martin Chuzzlewit. These peculiarities become distinctive features that the filter can seize on. It remains to be seen whether the filters will cope as well with the latest spam fad, which puts the entire message in an image rather than text.
On the defensive side, the hottest fads of the moment are SVMs and HMMs. SVM stands for support vector machine; it is an algorithm for clustering or classifying data. In an e-mail corpus each message can be assigned to a point in a high-dimensional space, where each dimension represents one of the features that distinguish spams from hams. An SVM attempts to find the hyperplane in this space that best separates the two sets of points.
An HMM is a hidden Markov model, a device currently popular in bio-informatics and speech recognition. HMMs are useful for inferring the hidden rules that govern a sequence of signals or symbols, such as the letters in a text. One possible application of HMMs in spam filtering is undoing the deliberate misspellings of words.
What is the long-term outlook for the spam problem? The gloomy view argues that we are caught in a tragedy of the commons. Economics favor the spammer; we may as well scrap e-mail and move on to the next channel of communication. The rosy forecast sees filters improving; so little spam will leak through that sending the stuff will become unprofitable, and the whole enterprise will collapse. (Bill Gates predicted that the problem would be licked by 2006.) The middle path is coexistence. Neither e-mail nor spam is driven to extinction.
Filters surely will improve, and yet there are lots of reasons to think that accuracy has a limit—and it's not 100 percent. For one thing, even people can't achieve perfect accuracy in classifying mail. William Yerazunis of the Mitsubishi Electric Research Laboratories, an expert on text classification, tried the experiment with his own mail and scored 99.84 percent.
Something else to keep in mind is that spammers could choose to improve quality rather than increase quantity. One conclusion I took away from my sodden experience of reading 10,000 spams was that if we can't have less spam, we really need better spam. And there's no reason why it all has to be so monotonous and unpalatable. Just because someone is selling a sleazy, counterfeit and probably illegal product doesn't mean the advertising has to be verbal and visual sludge. On the contrary, it's the worst products that need the best marketing (think of cigarettes). I suppose this is a way of saying that the end of spam is not death but transfiguration.
Finally, one premise of the entire anti-spam industry seems to me highly questionable—namely the assumption that every spammer's ultimate goal is to slither through the spam filter. As a text-classification system, a filter acts not to block a certain of class of mail but rather to sort messages into two categories—the inbox and the spam bin. Most of us look upon the spam bin as nothing more than a dung heap that has to be mucked out every now and then, but someone is finding information of value and interest there, or else spam would already have withered away. Seen from this point of view, a reliable filter serves the interests of the spammer as well as those of the recipient.
Diseases tend to evolve from an epidemic to an endemic state. For the first population exposed, the infection is dire and deadly; later, everyone gets a little sick but survives. It's not really in the pathogen's interest to kill the host; and although the host might well like to exterminate the disease, that seldom happens. The future of spam may be a low-grade fever.
© Brian Hayes
Click "American Scientist" to access home page

American Scientist Comments and Discussion
To discuss our articles or comment on them, please share them and tag American Scientist on social media platforms. Here are links to our profiles on Twitter, Facebook, and LinkedIn.
If we re-share your post, we will moderate comments/discussion following our comments policy.