
This Article From Issue
September-October 2011
Volume 99, Number 5
Page 426
DOI: 10.1511/2011.92.426
MAJORITY JUDGMENT: Measuring, Ranking, and Electing. Michel Balinski and Rida Laraki. xvi + 414 pp. The MIT Press, 2010. $40.
Majority Judgment is a lucidly written book in which Michel Balinski and Rida Laraki offer a compelling argument for rethinking the nature of voting—that is, how best to aggregate individual choices into a social choice. I have serious reservations about the specific solution they offer, a method of voting known as majority judgment. But I am not an unbiased observer, having long been an advocate of another system, approval voting, which shares some of the properties of majority judgment but which, like some other voting systems, may give very different outcomes, as I will show.
Ad Right
Balinski and Laraki jettison the traditional framework used in the analysis of social choice, made famous by Kenneth J. Arrow’s celebrated impossibility theorem 60 years ago. Arrow assumed that voters rank candidates (or other alternatives) from best to worst and proved that four “reasonable” conditions for aggregating voter preferences are mutually inconsistent, which suggested to some that the social-choice problem was insoluble. The authors offer a critical review of this literature, proving several of its important theorems; this discussion abets a comparison with their own mathematical results, which are grounded in axioms. The book also includes many empirical and experimental examples, supported by astute history-of-science observations and rigorous statistical analysis. All of this makes for a rich interdisciplinary treatment of voting theory, which is arguably the foundation of democracy.
The singular contribution of this book is prescriptive: Balinski and Laraki propose that voters grade candidates rather than rank them and that these grades be aggregated in a particular way—if there is to be a single winner, the candidate with the highest median grade should be elected. They illustrate their argument by using the six grades used in French schools (Balinski and Laraki are associated with the Laboratoire d’Économétrie in France): Excellent, Very Good, Good, Acceptable, Poor and Reject.
The authors assert that it is the verbalized forms of the grades, not numerical points, that voters should use to rate candidates, at least insofar as there is a “common language” whereby the words convey more or less the same meaning to all voters. Although this is a tall order in many voting situations, it is not so difficult in several interesting cases that Balinski and Laraki discuss, such as wine and figure-skating competitions, in which expert judges—the voters—presumably apply similar standards.
But why use the highest median rather than the highest mean grade—assuming there is an underlying interval scale that allows for averaging—to determine a winner? In fact, both of these standards share a problem. For example, suppose five voters give candidates A and B the following grades (the voters are aligned with the grades they have given to each candidate):
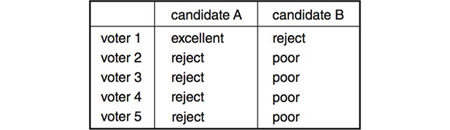
If one were to convert these word grades to a six-grade equal-interval numerical scale of 6, 5, 4, 3, 2, 1 from best to worst, the mean would favor A (2, or Poor for A; 1.8, or slightly worse than Poor for B), even though four out of five voters prefer B, whose median grade is Poor (A’s median grade is Reject).
But the tables are turned if the five voters give A and B the following grades:
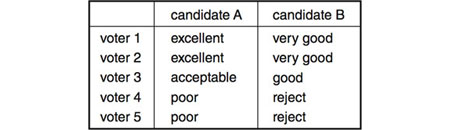
Now the median favors B over A (A’s median grade is Acceptable and B’s is Good), even though four out of five voters prefer A, who is the mean choice (with a mean grade of 3.8, or almost Very Good, for A, versus 3.2, or slightly better than Acceptable, for B).
If the voters were restricted to just two grades, Approve or Not Approve, then B would win in the first example and A in the second example, assuming that voters would choose Approve only for the candidate to whom they gave the higher grade and whom they therefore presumably prefer. Under this system, known as approval voting, note that B and A, respectively, win by decisive scores of 4 to 1 in the first and second examples.
These examples can readily be extended to include races with more than two candidates. For simplicity, I’ve used only two candidates to illustrate how the mean, the median and approval voting can lead to three different outcomes in the two examples.
Which grading system is best? Balinski and Laraki argue that choosing the candidate with the highest median grade, which they call majority judgment, is better than approval voting, because it allows voters to express themselves more fully; and it is better than using the mean, which is called “range voting” or “score voting,” because it is less manipulable, among other reasons.
To illustrate manipulability, let us return to the first example. If two of the four voters who gave a grade of Poor to their preferred candidate, B, raised their grade of candidate B to Acceptable, B would be the range-voting winner, with a mean grade of 2.2, or slightly better than Poor. So by slightly exaggerating the grade they give to their preferred candidate, they can induce his or her election, which is a form of strategic voting.
But the median winner in the second example, candidate A, is also vulnerable. If the voters who gave grades of Poor to A, who is their preferred candidate, moved to the extreme and gave candidate A grades of Excellent, then A would have a median grade of Excellent and would defeat candidate B, whose median grade would still be Good.
This illustrates that majority judgment, too, is vulnerable to strategic voting. Although the median cannot be altered if voters exaggerate but stay on the same side of the median (for example, if those who gave candidate A a grade of Poor had not raised their grade above Acceptable), when they do not stick to their side, they can indeed manipulate the outcome to their advantage under majority judgment as well as range voting, as Balinski and Laraki acknowledge.
Although the median is generally less manipulable than the mean, which would seem to favor majority judgment over range voting, majority judgment suffers from a bizarre problem that range voting and approval voting do not—its vulnerability to the “no-show paradox,” as illustrated by the following example, in which five voters give candidates A and B the following grades:
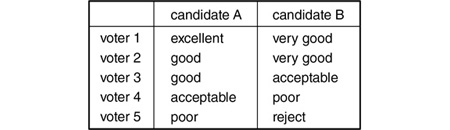
Notice that all three voting systems, including approval voting, render A the winner, and that A receives a higher grade than B from every voter except the second one.
Now suppose that two new voters show up, and each gives a grade of Excellent to candidate A and a grade of Very Good to candidate B. These additions would not change the outcome under range and approval voting; in fact, they would give a bigger victory to A. By contrast, under majority judgment, the new median would be Very Good for B but would remain Good for A, so B would win, even though it was A who received more support from the new voters.
Although the new voters have given higher grades to A than to B, their votes have backfired, electing B instead, so they would have been better off not showing up. This paradox is clearly antithetical to democratic choice—more support should help, not hurt. The authors acknowledge that majority judgment is vulnerable to the no-show paradox, but they dismiss this as “of little real importance” in practice.
Majority judgment is not the only system in which additional support can sometimes hurt a candidate. In some systems—such as the Hare system of single transferable vote (also known as the alternative vote or instant-runoff voting), which is used in Australia, among other places—voters rank all of the candidates. Those who receive the fewest first-choice votes are sequentially eliminated, and the votes cast for them are transferred to the next-lower choice who remains until one candidate receives a majority. Under this system, a voter who raises a candidate in his or her ranking can actually cause that candidate to lose. Voting systems that allow this to occur are said to be nonmonotonic.
Balinski and Laraki say that the property of monotonicity is critical: Any method that lacks monotonicity should be disqualified. But nonmonotonicity is intimately related to the no-show paradox—the underlying problem of both pathologies is that more support hurts a candidate. It therefore seems to me that the authors are being inconsistent in not disqualifying majority judgment because of its vulnerability to the no-show paradox.
Balinski and Laraki are not the first to propose use of the median, but they are the first to address the problem of ties (with only six grades, two or more candidates could easily tie for the highest median grade). They suggest an elaborate set of rules for breaking ties. These are plausible, but there are other tie-breaking rules that would probably work just as well.
One of the strengths of Majority Judgment is its discussion of applications of the method to different types of contests. In addition to wine and figure skating, there are other competitions (the authors discuss piano, diving and gymnastic competitions) in which judges grade contestants. In some types of contests, either fewer gradations (as illustrated by approval voting) or more (up to 100 gradations have been suggested by some proponents of range voting) might work better.
Although in many competitions winning is the name of the game, in others taking second or third place is considered meritorious and noteworthy. In the latter contests, judges are likely to make nuanced distinctions in evaluating contestants, rather than giving only maximum and minimum grades to them.
But in many political elections, I’m afraid, voters would do exactly that, giving their favorites the maximum grade and their most serious competitors the minimum grade. The publication of polls on the relative standings of candidates, and the advice of political pundits, would encourage this bifurcation of grades, which is equivalent to grading under approval voting. It is true that in experiments with majority judgment in French elections, many voters gave intermediate grades to candidates, but I would argue that they did so because they knew this was only an experiment and thus felt that they could afford to be honest.
In the dozen or so professional societies in which approval voting has been used, voters often approve of two or more candidates in races that have five or more contestants. In major public elections with three or four major candidates, a centrist is likely to receive support not only from centrist voters but also from moderate left and moderate right voters and, therefore, will be more likely to win under majority judgment than plurality voting. But majority judgment would probably not favor centrists to the extent that range and approval voting would; as a case in point, using as evidence data from an experiment in Orsay, France, Balinski and Laraki argue that in the 2007 French presidential election, centrist François Bayrou probably would not have won under majority judgment.
Majority judgment seems best suited for contests in which winning isn’t everything, so that jurors’ judgments are more likely to be sincere. The difficulty of manipulating the median should also foster sincerity under this system. But the susceptibility of majority judgment to the no-show paradox is a serious problem, in my opinion, and so is the lack of a common language to assess political candidates, especially in a country like the United States in which cultural differences are significant and partisanship runs high.
Balinski and Laraki have made a provocative case for using majority judgment in evaluating contestants; their case for using it in political elections is weaker. More important, they have expertly presented the benefits of grading candidates, as opposed to ranking them. For too long the latter perspective has dominated the study of social-choice theory.
Steven J. Brams is professor of politics at New York University. He is coauthor with Peter C. Fishburn of Approval Voting (Springer, 1983; second edition, 2007) and is the author of Mathematics and Democracy: Designing Better Voting and Fair-Division Procedures (Princeton University Press, 2008). His latest book is Game Theory and the Humanities: Bridging Two Worlds (The MIT Press, 2011).

American Scientist Comments and Discussion
To discuss our articles or comment on them, please share them and tag American Scientist on social media platforms. Here are links to our profiles on Twitter, Facebook, and LinkedIn.
If we re-share your post, we will moderate comments/discussion following our comments policy.