Crawling toward a Wiser Web
By Brian Hayes
Computing with data sets as large as the World Wide Web was once the exclusive prerogative of large corporations; the Common Crawl gives the rest of us a chance.
Computing with data sets as large as the World Wide Web was once the exclusive prerogative of large corporations; the Common Crawl gives the rest of us a chance.

DOI: 10.1511/2015.114.184
To put all human knowledge at everyone’s fingertips—that was the grandiose vision of Paul Otlet, a Belgian librarian and entrepreneur. Starting in the 1890s, he copied snippets of text onto index cards, which he classified, cross-referenced, and filed in hundreds of wooden drawers. The collection eventually grew to 12 million cards, tended by a staff of “bibliologists.” Otlet aimed to compile “an inventory of all that has been written at all times, in all languages, and on all subjects.” The archive in Brussels was open to the public, and queries were also answered by mail or telegram. In other words, Otlet was running a search engine 100 years before Google came along.
In 2015, knowledge at your fingertips is no longer an idle dream. Although not everything worth knowing is on the Internet, a few taps on a keyboard or a touchscreen will summon answers to an amazing variety of questions. The World Wide Web offers access to at least 10 10 documents, and perhaps as many as 1012; with the help of a search engine, any of those texts can be retrieved in seconds. Needless to say, it’s not done with three-by-five cards. Instant access to online literature depends on a vast infrastructure of computers, disk drives, and fiber-optic cables. The main work of Otlet’s bibliologists—the gathering, sorting, indexing, and ranking of documents—is now done by algorithms that require no human intervention.
For all the remarkable progress made over the past century, it’s important to keep in mind that we have not reached an end point in the evolution of information technology. There’s more to come. In particular, today’s search engines provide speedy access to any document, but that’s not the same as access to every document. Someday we may have handy tools capable of digesting the entire corpus of public online data in one gulp, delivering insights that can only emerge from such a global view. An ongoing project called the Common Crawl offers a glimpse of how that might work.
Suppose you’re watching an old movie on TV when a question crosses your mind: “What was John Wayne’s real name?” You submit the query to your favorite search engine, and the answer comes back in milliseconds. (Most likely you get two different answers, both of them correct.) How does the search engine deliver these results so quickly?
I hope I won’t be shattering any illusions by revealing that a search engine doesn’t actually go out and scour the entire Web in response to each query. Instead it consults a precompiled index, a list of pointers to documents that include various terms—for example, the words “John Wayne.” The index is constructed not from the Web itself but from a local replica of the Web, called a crawl, built by downloading each document and saving a copy. This private cache includes the text of each file, the HTML markup that defines the document’s structure (title, headings, paragraphs, and so on), as well as accompanying metadata such as where the document was found. Other resources embedded in the file, such as images, may or may not be saved. The crawl is the modern equivalent of Otlet’s bank of index cards.
Why is it called a crawl? When Tim Berners-Lee named his invention the World Wide Web, he set off a spate of arachnid allusions. In particular, programs that explore the structure of the Web, moving from node to node while gathering information, were called spiders or crawlers, and the trove of data such a program accumulates has come to be known as a crawl.
Indexing billions of documents is obviously a large undertaking, requiring a major investment in computers, storage, and communications bandwidth. When you submit a query to a search engine, you briefly become the master of this imposing apparatus; in effect, you are running a program on the crawl data set, using the search company’s hardware. However, you have only limited control over that program. You get to choose the search terms and perhaps a few other parameters, such as a date range, but everything else about the computation is determined by the owners of the data.
What if the public had direct access to the entire crawl, and everyone were welcome to write and run their own programs for analyzing the data? The Common Crawl offers just such an opportunity. The crawl conducted in January 2015 (the latest available as I am writing this) covers 1.8 billion web pages and fills 139 terabytes of disk space. Earlier crawls, going back to 2008, are also online. All of the data collections are freely available to anyone. Instructions for retrieving or working with the material are on the Common Crawl website: http://commoncrawl.org.
The Common Crawl is overseen by a nonprofit corporation, the Common Crawl Foundation, established in 2007 by Gil Elbaz, a software entrepreneur. (In the 1990s, Elbaz devised a scheme for matching advertisements to web pages; his company was later acquired by Google.) Work on the crawl is done by a small staff in San Francisco, and by volunteers.
The metaphor of a spider crawling over its web is a little misleading. It suggests a program that migrates from site to site on the Internet, running on one machine after another. In fact the program stays home, always running on its own host computer. The crawler’s “visits” to websites are merely requests for documents, the same as the requests you would issue from an ordinary web browser.
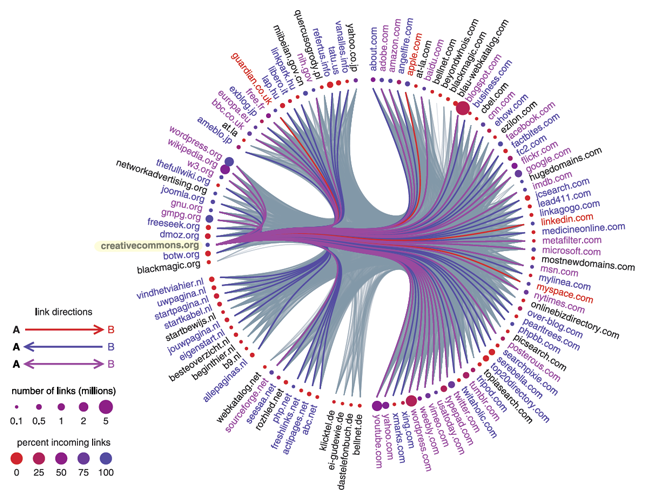
Illustration by Brian Hayes.
If you are very patient and methodical, you can crawl the Web manually. First set up two lists: a to-do list of web pages you plan to visit, and a been-there-done-that list of pages you’ve already seen. At the outset, the to-do list holds URLs that will serve as seeds, or starting points, for the crawl; the been-there list is initially empty. In a web browser, type in the first to-do URL. When the page has loaded, save it in a file, then look through it for links to other pages; add these URLs to the to-do list unless they are already present there or in the been-there list. Each page moves to the latter list after you visit it. Repeat these steps until the to-do list is empty, at which point you will have stored a copy of every web page that can be reached by following any chain of links from your seed URLs.
In a practical crawler, this algorithm needs a few tweaks. One problem is that not all interesting pages can be reached by following links from any one starting point; some outlying precincts of the Web are disconnected from the main body. Second, not all the pages reached are interesting; quite a few of them represent “web spam,” designed to manipulate search-engine rankings or advertising revenues. And some websites act as “spider traps,” either inadvertently or maliciously. Consider a site that offers a page of information about each integer from 1 to 1015. (Such sites exist!) A crawler following links from one page to the next would be stuck for thousands of years.
In this environment, a crawler needs some sensible limits on how far to pursue a sequence of links and guidance about which pages are worth recording. Stephen Merity, data scientist for the Common Crawl, explains that the group’s crawling strategy has evolved away from pure reliance on discovering and following links. The crawl’s to-do list now begins with a large set of URLs donated by the search engine Blekko. During the crawl the list of discovered links is pruned to reduce the volume of spam and escape spider traps. The aim is to give precedence to pages of interest to human readers.
The major search engines operate warehouse-scale data centers with thousands of computers. The Common Crawl Foundation has no such facilities. Instead all of the crawling is done through Amazon Web Services (AWS), the “cloud computing” division of Amazon.com.
A major incentive for this arrangement is that AWS waives all storage fees for the Common Crawl data (and for about 50 other data sets deemed to be of wide public interest, such as census returns and weather observations). A quirk of the AWS pricing policy provides a further benefit: There is no charge for communication bandwidth for data flowing into AWS, which comprises most of the traffic during a crawl. What remains to be paid is the cost of computation. A crawl in progress occupies 100 to 150 computer “instances,” or virtual machines. Merity notes that most of the work can be done with spot-market instances, which come at a discount because they can be shut down without notice. The overall computing bill is $2,000 to $4,000 a month.
For a consumer of the data, the economic calculus is somewhat different. All of the Common Crawl data sets are available for download without charge, but you’ll need a high-speed Internet connection and someplace to put the files, which will fill perhaps two dozen of the largest readily available disk drives. Depending on what kind of processing or analysis you have in mind, you may also need a cluster of computers.
The alternative is to do the analysis on AWS, eliminating the need to move and store the data but incurring hourly charges for the use of computing capacity. Merity reports that uncomplicated tasks can often be completed for less than $50.
Most large-scale computations on the crawl data are done with a method known as map-reduce. The first phase of the computation (the mapping part) applies a single algorithm to many small chunks of the data set, so that all the work can be done in parallel on multiple machines. The reduction step gathers and combines the outputs of the mapping operations to compute a final answer. A simple example of the map-reduce paradigm counts the occurrences of all words in a collection of documents. The mapping procedure, applied to each document separately, outputs a list of words with their frequencies in the document. The reduction program collates and sums the word counts. A software framework called Hadoop provides an armature for building map-reduce programs.
Probing the Common Crawl data set is not yet as easy as asking a search engine trivial questions about movie stars. Digesting terabytes of data requires skill and persistence, but the effort has proved worthwhile for a number of research groups and at least a few intrepid individuals. The Common Crawl website lists more than 30 publications based on studies of the data.
Linguists have been the most enthusiastic early adopters. Jason Smith of Johns Hopkins University and five colleagues collected examples of parallel text in different languages. Such matched passages are the raw material for a data-driven approach to automated translation. The search identified 34 million pairs of sentences with parallel text in English and one of 18 other languages.
Calvin Ardi and John Heidemann of the University of Southern California went looking for parallel texts of another kind: web pages that copy content from elsewhere on the Internet, often for shady purposes. They found some 80 million “bad neighborhoods” with a notably high percentage of duplicated content. But they also found that much of the copied material is not plagiaristic but mere “boilerplate” from templates and program libraries.
Willem Robert van Hage and his colleagues in the Netherlands have tallied the frequency of numbers appearing on web pages. Small integers are surely more abundant than large ones, but how does the frequency fall off as a function of magnitude? Some months ago I tried to answer this question myself by submitting numeric search-engine queries and recording the result count. Without knowing the details of how the search engine parses and classifies numbers, it was hard to interpret the results. The van Hage group, applying their own number-recognition pattern, found that a number’s frequency is inversely proportional to its magnitude. But they also found many anomalies, such as a spike for the number 2012 (which is the year the data were gathered).
Ross Fairbanks, a software developer in Spain, has created the website WikiReverse by mining the Common Crawl for links pointing to Wikipedia articles. For example, the Wikipedia entry for “meme” (“an idea, behavior, or style that spreads from person to person within a culture”) has 3,112 incoming links from 1,373 sites. The Wikipedia articles with the largest numbers of inbound links turn out to be rather bland: “web traffic,” “United States,” “India.”
Another category of studies ignores the content of pages and merely considers the topological structure of the Web—the network of connections between pages or sites, defined by links. From this point of view, the Web is a mathematical object called a directed graph: Each page is a node of the graph, and each link is an “arc” pointing from one node to another.
Fifteen years ago Andrei Broder and his colleagues, working with the AltaVista search engine, published a pioneering study of a web graph with 200 million nodes and 1.5 billion arcs. They found that about a quarter of the pages formed a “strongly connected component,” meaning that you could travel between any two pages in this set by following some sequence of links. Most other pages in the sample had links either into or out of this core component, but not both.
Robert Meusel and his colleagues at the University of Mannheim in Germany have reexamined these conclusions, using the Common Crawl 2012 data set, which is 20 times larger. They find that the strongly connected component includes a much larger share of the nodes—more than half instead of a quarter. To some extent, this change may reflect the evolution of the Web, which has become more densely interconnected as it has grown larger. But the Mannheim group also reports evidence that such structural properties are highly sensitive to details of the crawl procedure. In particular, more recent Common Crawl data, collected with the Blekko-seeded algorithm, yield a sparser graph; the largest strongly connected component has only 19 percent of the nodes. Thus some basic questions about the true topology of the Web remain unsettled.
The Mannheim group’s data are online at http://webdatacommons.org. Because the files include only links between pages, without text or other content, they are much smaller than the full crawl. The smallest data set, which records links between whole websites rather than individual pages, is compact enough that some kinds of analysis can be done on a laptop.
For the present, the Common Crawl can be seen as a public resource, as a research platform, and as a playground for ambitious programmers. It has not yet infiltrated the daily lives of ordinary Internet users, in the way that search engines have become an annex to human memory. Nevertheless, the Common Crawl may offer some clues to how we will navigate the information landscapes of the future.
The remarkable success of search engines can be attributed in part to a very clever trick: They harness the speed and power of computation, but they also sneak some human judgment into their algorithms. They do so by taking the graph structure of the Web as a guide to the importance of documents. Links from one page to another—placed there by human authors—can be interpreted as votes of confidence. That information is harvested from a web crawl and used to rank the documents.
Much more can be squeezed out of the crawl data. One active area of research is mining web pages for facts that allow a system to answer questions directly rather than just pointing to documents where answers might be found. Both Google and Bing attempt to respond in this way for certain queries; other examples are Apple’s Siri, IBM’s Watson, and Wolfram Alpha. All of these projects come from large organizations that keep their methods and data private. The Common Crawl may allow smaller groups to experiment.
Paul Otlet’s “inventory of all that has been written” sounds like one of those goals we strive to attain without ever expecting to succeed. Yet, suddenly, we’re awfully close. Universal access to all textual information is no longer a technological challenge. If it weren’t for legal and economic barriers, everyone could have a library card with unlimited borrowing privileges. What’s not unlimited is the human capacity to absorb, digest, and make productive use of all that knowledge. I submit there is no shame in admitting that we need computational help.
© Brian Hayes
Click "American Scientist" to access home page
American Scientist Comments and Discussion
To discuss our articles or comment on them, please share them and tag American Scientist on social media platforms. Here are links to our profiles on Twitter, Facebook, and LinkedIn.
If we re-share your post, we will moderate comments/discussion following our comments policy.